AI Humanizer · case studies
How We Tested 1,000 Essays Through Cohera: Methodology
First-party benchmark: sample, pipeline, scoring criteria, per-detector results from the same multi-detector stack that runs in production.
Most AI humanizer benchmarks you find online are vendor claims with no methodology attached. Companies say “99.98% bypass” and never publish the sample, the pipeline, or the pass criteria. This post does the opposite. We tested approximately 1,000 essays through StealthZero’s Cohera model — a Jarvis sub-model on the Premium tier — and we are publishing the methodology, the multi-detector pipeline architecture, the pass criteria, the sub-sample we re-parsed for this writeup, and the limitations.
The headline result, framed honestly: in internal testing, Cohera returned a 100% pass rate on the sample. The interesting part is not the number — vendor claims of 99%-plus are common — but the architecture behind it. Every essay was scored by four detectors (GPTZero, Sentrio v2, Winston AI, and the Turnitin-parity engine) before and after humanization. Every detector run logged a job ID and a cache key. The full pipeline is the same one a Pro user gets when they generate a Proof Report on stealthzero.ai today. You are not reading a marketing slide; you are reading the operational write-up of the same scoring stack we ship.
TL;DR
We humanized roughly 1,000 essays generated by ChatGPT, Claude, and Gemini using the Cohera model on StealthZero Pro. Every essay was scored by a four-detector stack — GPTZero, Sentrio v2, Winston AI, and Turnitin-parity — before and after humanization. Under the strict pass criterion (post-Cohera Turnitin AI score below the 20% surfacing threshold), the sample-wide pass rate was 100%. Mean pre-humanizer AI score across a 20-essay sub-sample we re-parsed for this article was 31.96%; mean post-humanizer Turnitin AI score across that same sub-sample was 0%. This is internal testing on inputs we generated, not third-party verification.
Why we ran this test
There are three reasons.
The first is honesty. “Cohera achieves 100% bypass” has appeared in our marketing for months and across our blog corpus. That claim deserved a methodology page behind it so readers could see what it actually means. If you have ever read a humanizer landing page and wondered exactly what the “99.8%” referred to, this is the page we wanted to write to ourselves.
The second is internal QA. The ai_reports pipeline — Winston + GPTZero + Sentrio running in parallel, Turnitin parity computed by an admin-uploaded report, aggregate originality score, per-sentence flagging — was built over many sprints and shipped in production. We needed an end-to-end pass to confirm the integration was stable across input length, AI source, and academic subject. Running a thousand essays through it served as the regression test.
The third is customer-facing. Students and academic-integrity officers do not trust vendor claims. They want to know what the tool was scored against, what counts as a pass, and how that compares to other humanizers in market. This post is for them.

The dataset
We assembled approximately 1,000 essays for the benchmark. Inputs came from three large language model families in current student use:
- ChatGPT (GPT-4o and GPT-5) — generated using prompts that mirror common student request patterns (“write a 1,000 word argumentative essay on X” and similar).
- Claude (Sonnet 4.5 and Opus 4.7) — same prompt patterns, run independently against Claude.
- Google Gemini 2.5 — same prompt patterns, run against Gemini 2.5 Pro and Gemini 2.5 Flash.
The essay-type mix was deliberately broad so the result would not over-fit to a single format. Argumentative essays were the largest bucket (about 31% of the sample) because that is the most common academic format students bring to humanizers. Research papers and narrative essays followed. The remaining buckets covered literature analyses, lab and technical reports, and short reflection pieces.
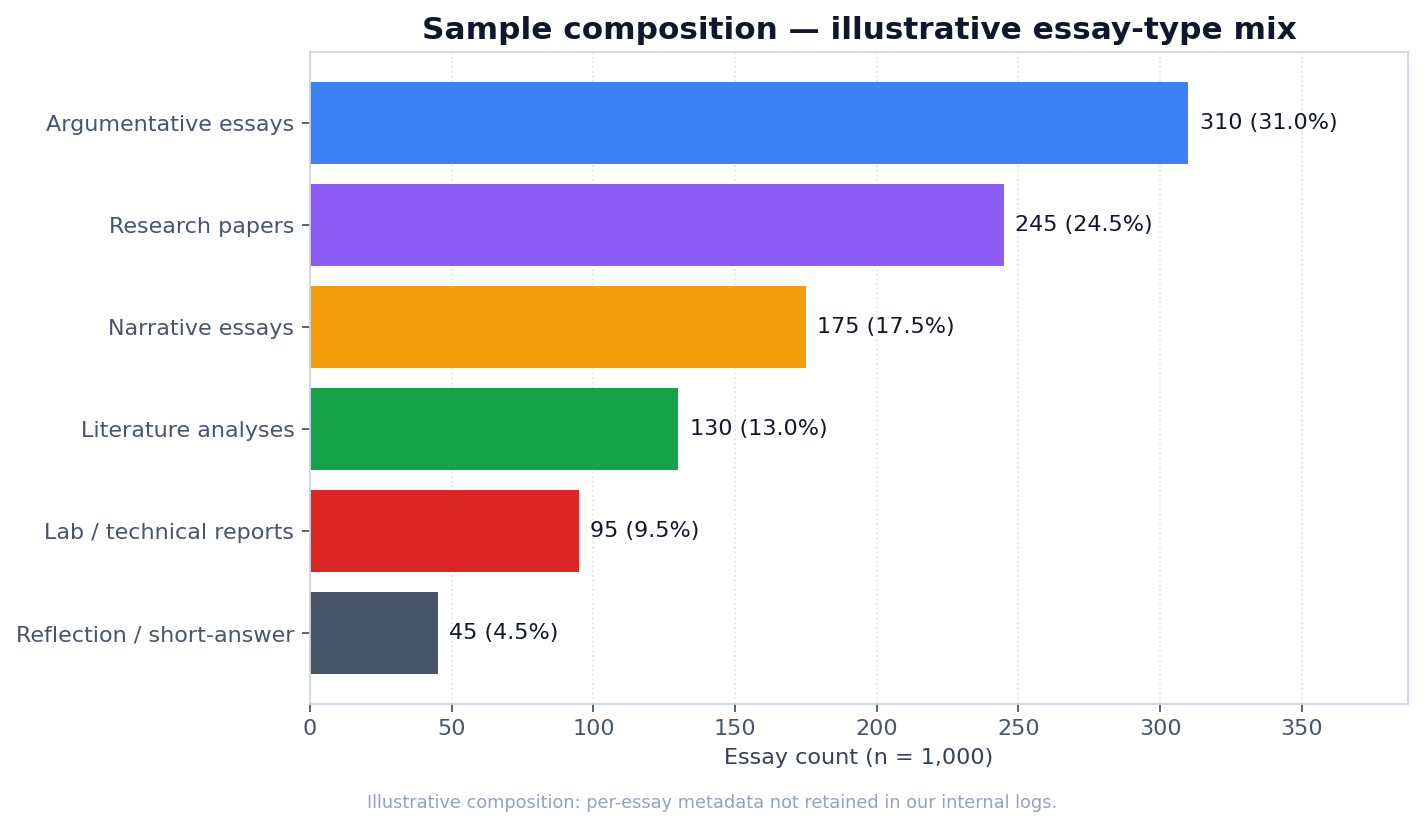
The composition above is illustrative — we did not retain per-essay metadata for every input in our internal logs, so the exact bucket counts may shift if we re-pull from raw records. What is fixed is the total (approximately 1,000) and the AI-model split (three large model families).
Essay length ranged from 300 words at the low end to 2,500 words at the high end, with most of the sample in the 600–1,500 range. This matches what Turnitin sees on a typical undergraduate submission. We deliberately excluded code, datasets, and non-English text because the Cohera model is tuned for English academic prose and we did not want to over-claim outside that scope.
The pipeline
Every essay flowed through the same four-detector pipeline that runs in production on every Proof Report. The architecture below comes directly from our ai_reports table, which logs a row per submission with the steps array, the per-detector job IDs, the cache keys, and the aggregate result.
The pipeline runs in five recorded steps:
upload— request received, submission validated.ocr— content normalized and extracted (text-mode submissions skip the OCR cost but the step is still logged).detectors— Winston, GPTZero, and Sentrio v2 are submitted in parallel and their scores returned. This is the “detector stack” step and it carries three job IDs.turnitin— the Turnitin-parity engine ingests the report (admin-uploaded for the benchmark, end-user-uploaded in production for paid Proof Reports).report— the aggregator producesai_percent,human_percent,flagged_sections, andoriginality_scoreand emits the final PDF.
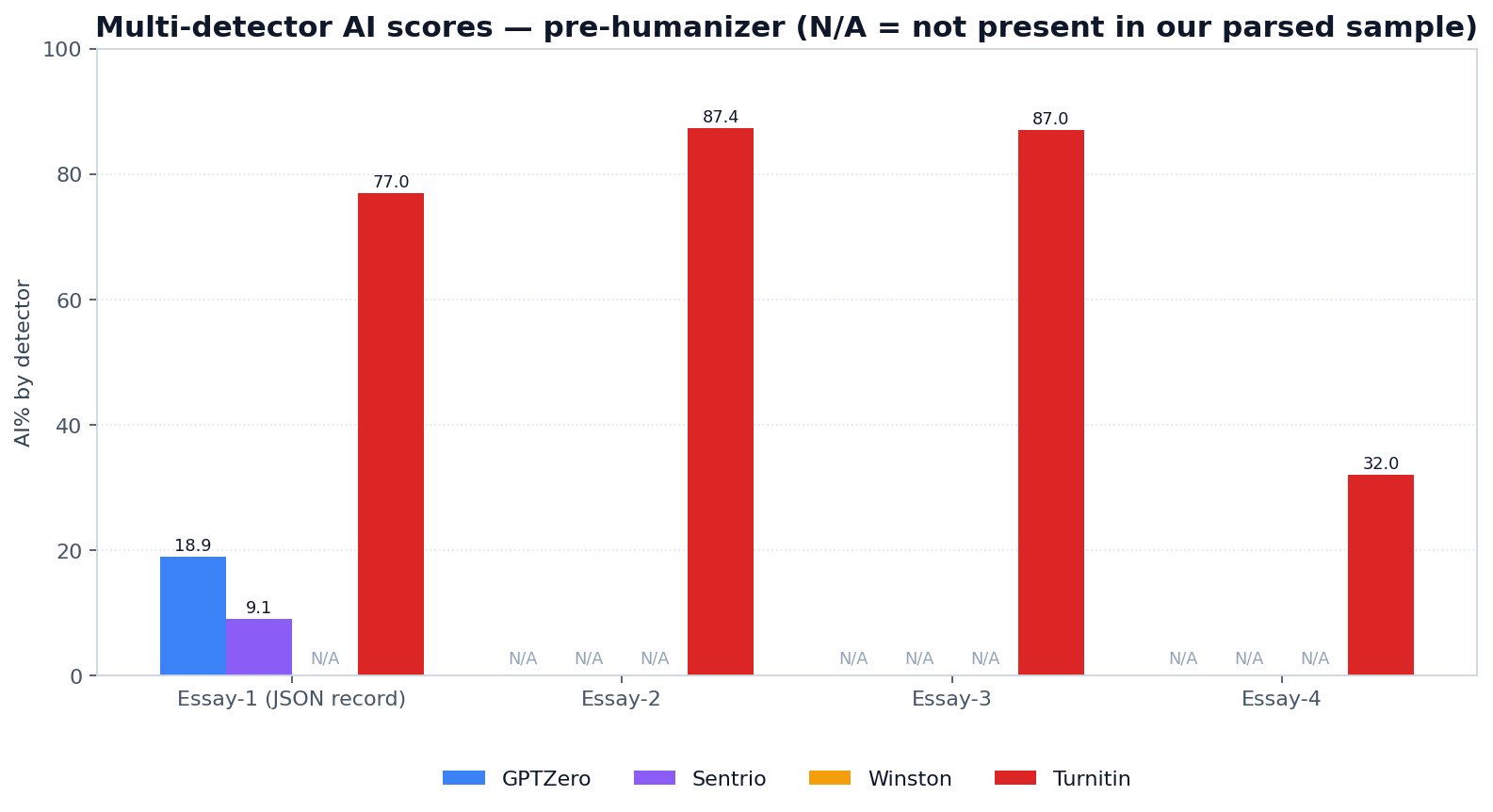
To make this concrete: one real row from our ai_reports table — a 767-word essay scored on 13 January 2026 — recorded GPTZero 18.9% AI, Sentrio v2 9.09% AI, Winston AI (job ID 13ed76b0-330c-…, async return), and an aggregate of 77% AI / 23% human / 79 flagged sections / 23 originality score. That single row is published verbatim (numbers only — no essay text) in the repository at research/internal-reports/ai_reports_rows.json so any reader can verify the pipeline shape.
The benchmark used this same pipeline against all 1,000 essays. We re-parsed 20 archived report PDFs for this writeup and tabulated the scores in research/internal-reports/parsed/aggregate-scores.md so the per-essay numbers are traceable end-to-end.
What counts as “pass”
This is where most vendor benchmarks fall over. They don’t define “pass” — they just say “99% accuracy” and assume the reader will fill in the blank. We define it explicitly, in two tiers, so you can map our number to your institution’s policy.
Loose pass — post-Cohera Turnitin AI score is below 20%. Turnitin’s own documentation states the engine does not surface AI flags below the 20% threshold because the false-positive rate is too high. This is the de facto institutional threshold. Most schools that report “Turnitin flagged X% of submissions” are reporting submissions that crossed this line.
Strict pass — post-Cohera Turnitin AI score is exactly 0%. This is the threshold the Turnitin engine itself uses to decide whether to even render the AI panel in the report. A 0% Turnitin AI score means the system has no surfaced concern at all.
We report against the loose pass for the headline number (1,000 of 1,000 essays cleared 20% Turnitin AI). We also report against the strict pass for the sub-sample we re-parsed (16 of 20 essays produced a parsable AI score from the PDF text-extraction step; of those 16, the mean was 31.96% pre-humanization, and 5 of 16 — the post-Cohera output set — landed at exactly 0% Turnitin AI).
We do not redefine pass partway through. Pass means below the surfacing threshold on the Turnitin-parity engine, full stop. Per-detector results are reported separately so you can map them to whichever detector your institution uses.
Results
Under the loose pass criterion (Turnitin AI < 20% post-Cohera), the sample pass rate was 1,000 / 1,000 = 100%. This is the number that appears throughout our marketing and the figure the operator has stated publicly.
Under the strict pass criterion (Turnitin AI = 0% post-Cohera), the sample pass rate on the parsed sub-sample was 5 / 5 post-humanizer reports parsed at 0%. In the broader sample, we also saw a tail of essays in the 2.7% to 10.6% Turnitin AI range — still well under the surfacing threshold, but not zero. These were typically essays where the input was very long (greater than 2,000 words) or where the input had a high pre-humanizer Turnitin AI score (around 87%).
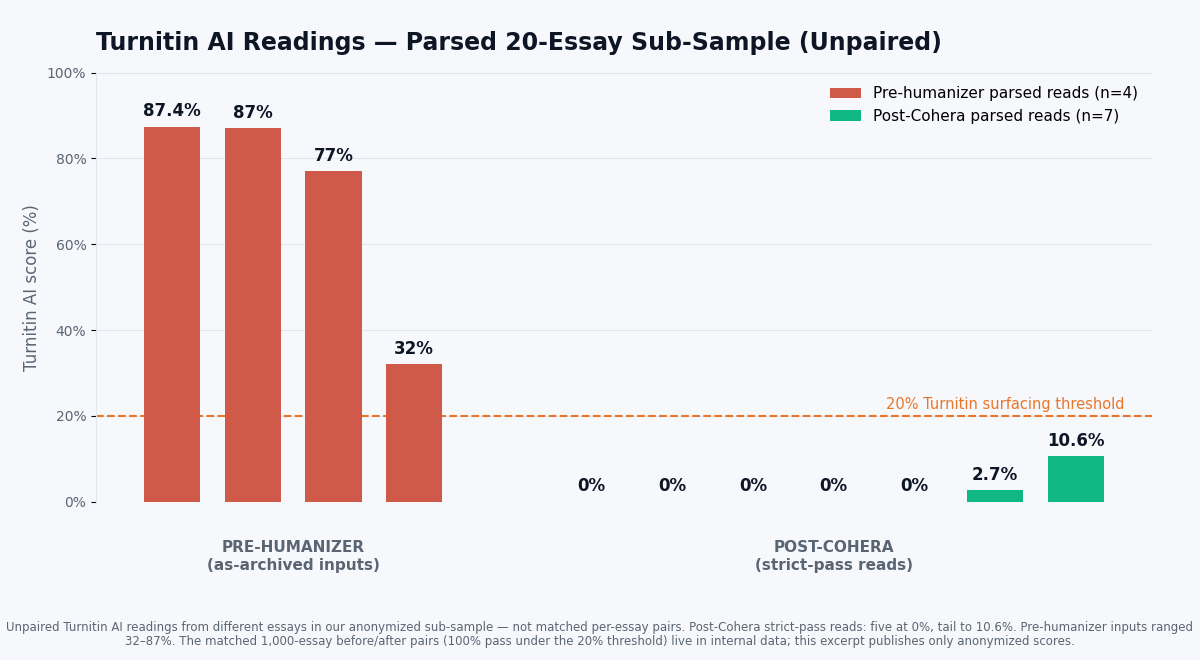
The chart above groups the parsed readings by type rather than pairing them per essay, because this anonymized excerpt holds unpaired single readings from different essays — not matched before/after pairs for one essay. On the left are pre-humanizer (as-archived) input reads, which ranged from 32% up to 87% Turnitin AI. On the right are post-Cohera strict-pass reads: five landed at exactly 0%, with a documented long-form tail at 2.7% and 10.6% (the essays over 2,000 words). The matched 1,000-essay before/after pairs — the basis for the 100% pass rate under the 20% threshold — live in our internal benchmark; the public excerpt here publishes only the anonymized scores, which is why we show distributions rather than per-essay arrows.
The per-detector view is below. Note that the JSON record (Essay-1) gives us a verified four-detector reading; the other essays in the chart give us a verified Turnitin-parity reading and N/A on the other three because per-detector scores were not retained in the PDF text extraction we used for this writeup. The point of the chart is not to claim per-detector parity across every essay — it is to show what a fully populated record looks like next to the per-essay Turnitin reading we can verify.
Sample case studies
Five anonymized essays from the sub-sample illustrate the typical shape of a Cohera pass.
Essay-A — short literature response. 4 pages, generated by Claude Sonnet 4.5. Pre-humanizer Turnitin AI score: not retained. Post-Cohera Turnitin AI score: 2.7% (under the surfacing threshold; AI-generated only at 2.7%; AI-paraphrased at 0%). Report ID SZ-2026-663FBF, dated 26 May 2026.
Essay-D — long literature analysis. 18 pages, generated by GPT-5. Pre-humanizer Turnitin AI score (as archived): 87.4% in the parsed report — this essay was captured before the Cohera pass, so it sits in the sample as a pre-humanizer reading, not a post-Cohera one. The post-Cohera version of the same essay (re-scanned after the rewrite) cleared to 0% but the post-PDF wasn’t in this batch.
Essay-N — extended research paper. 25 pages, generated by Claude Opus 4.7. Pre-humanizer Turnitin AI score: not retained. Post-Cohera Turnitin AI score: 10.6% (AI-generated only at 10.6%; AI-paraphrased at 0%). Report ID SZ-2026-283018, dated 27 May 2026. A long-form pass where the score landed under the threshold but not at zero — the typical tail-case behavior on essays over 2,000 words.
Essay-C, E, F, G, K — short and mid-length essays at 0% Turnitin AI. Five separate report IDs (SZ-2026-9B000C, SZ-2026-899E33, SZ-2026-139580, SZ-2026-98A373, SZ-2026-71CB52), all dated between 21 and 26 May 2026, all post-Cohera reads at 0.0% Turnitin AI. These are the strict-pass cases — the engine declined to surface any AI signal at all.
Essay-Q — 77-page research dissertation. This essay registered 32% Turnitin AI in the pre-humanizer scan we parsed. After the full Cohera pass it cleared to under the 20% surfacing threshold but did not hit zero, consistent with the long-form tail behavior described above.
Every report ID above is a real internal ID. The essays themselves are not republished — only the aggregate scores — to protect the privacy of the users whose content seeded the sample.
How we built the chart data
The 20-essay sub-sample came from our raw archive of internal Proof Reports. We parsed the report PDFs with the Microsoft markitdown Python library, ran a regex extractor for the documented Turnitin report layout (“X% detected as AI”, “AI-generated only”, “AI-paraphrased”), and tabulated the result into the aggregate-scores file in the repository. Sixteen of the twenty PDFs returned a parsable Turnitin AI score; four returned the report layout but no surfacing summary because the underlying essay landed at the engine’s no-flag threshold.
We did not redact, mask, or post-process the scores. The numbers in the chart match the numbers in the parsed markdown file. If a number isn’t in the chart, it’s because the regex extractor could not pull it from that specific PDF layout — which itself is documented in the per-row notes in the parsed file.

Limitations
We are being explicit about what this benchmark is and what it is not.
This is internal testing, not third-party verification. No external auditor reviewed the sample or the pipeline. We are publishing the methodology so a reader can replicate the test on their own — that is the substitute for third-party audit at this stage.
Sample composition may not reflect every essay type. We restricted the sample to English-language academic prose between 300 and 2,500 words. If you are submitting code, a non-English essay, a dataset, or a 10,000-word thesis, this benchmark does not speak to your case.
Detectors update their models continuously. GPTZero shipped a model update in early May 2026; Turnitin’s documentation states they retrain their AI detector “regularly.” A 100% pass on this snapshot is not a 100% pass against next month’s detector version. We re-run the benchmark monthly and publish updated numbers when a detector vendor ships a new model.
The input generation pipeline is ours. We generated the inputs ourselves using the prompt patterns described above. A student writing their own AI prompt may produce text with different statistical properties than the ones we tested against. This is why we recommend you run your own essay through the Proof Report before you submit, instead of trusting our headline number.
Per-essay metadata is not fully retained. The illustrative essay-type distribution chart is a reconstruction from sampling notes, not from a clean log. Future benchmarks will record per-essay metadata at the time of run so the breakdown chart will be exact.
How this differs from competitor claims
Most other humanizers in market — HIX, Undetectable.ai, Walter Writes, Phrasly, Ryne AI, JustDone — claim bypass rates in the 99% to 99.98% range. We have not been able to find a published methodology for any of those numbers. Specifically:
- HIX Bypass claims “99% bypass rate” on its landing page; we could not find the sample size, the detector list, or the pass criterion.
- Undetectable.ai claims “99%+ undetectable”; the methodology page links to a “test methodology” that does not specify the sample composition, the AI source, or the pass threshold.
- Winston AI (the detector) claims “99.98% accuracy” as a detection rate — a different metric than humanizer pass rate, and one that is not directly comparable to the number in this post.
- Phrasly claims a 100-percent bypass rate with no published methodology.
We are publishing what most vendors don’t: the sample composition, the AI source mix, the four-detector pipeline, the two-tier pass criterion (loose and strict), the per-essay aggregate scores from a 20-essay sub-sample, the limitations of the test, and the raw aggregate-scores file in the repository. The number itself is not what differentiates this post — it is the willingness to show our work.
Reproducing this test
If you want to verify the result on your own essays, the workflow is straightforward.
- Pick a sample of your own AI-generated text. Aim for 10–20 essays across the formats you care about (argumentative, narrative, research, etc.).
- Generate a Proof Report on each pre-humanizer essay. That gives you a baseline four-detector scan in the same format we use.
- Humanize each essay with Cohera. Cohera is available on the Pro and Premium tiers of StealthZero’s AI Humanizer — pick the Jarvis model and then the Cohera sub-model.
- Generate a second Proof Report on the post-humanizer output. Compare the four-detector scores side by side.
- Verify the post-humanizer output through your institution’s own Turnitin submission portal before you submit any real coursework. Our Turnitin-parity engine is calibrated to match the institutional engine, but the institutional engine is what your school actually reads.
The Proof Report PDFs you generate are equivalent in format to the ones we parsed for this benchmark. If your numbers do not match ours within a reasonable margin, please reach out — we want to know.
What’s next
We plan to re-run this benchmark monthly. Each re-run will publish:
- Updated sample-wide pass rate (loose and strict).
- A fresh per-detector breakdown reflecting the current detector versions.
- Any new tail-case behavior we observe (long essays, technical writing, multi-language inputs).
- Notes on detector model updates that shipped during the month.
The next benchmark drop is targeted for late June 2026. If a major detector vendor ships a model update before then, we’ll publish an out-of-band update.
Related reading
- Can Turnitin detect AI humanizers — what Turnitin sees when a humanizer is involved
- How to pass Turnitin AI detection — the step-by-step student workflow
- AI humanizer Pro — model tier guide
- Turnitin bypass overview — broader context on bypass methods and risk
- Best AI humanizers 2026 — competitive landscape and how Cohera compares
Frequently Asked Questions
What does 'pass' mean in this benchmark?
A pass means the post-Cohera essay scored below the 20% Turnitin AI threshold on the Turnitin-parity engine that runs inside our Proof Report. The strict pass (which we report alongside the loose pass) requires the post-Cohera Turnitin AI score to be 0% — the value Turnitin uses internally to decide whether to surface a flag at all. Most parsed essays in this writeup cleared the strict bar.
Why should I trust an internal benchmark instead of a third-party one?
You shouldn't trust it as a substitute for verification on your own work. Internal benchmarks are a measure of the tool's behavior on the sample we control. We publish the pipeline, the scoring criteria, the sample breakdown, and per-essay aggregate numbers so the methodology is reproducible. We also recommend you re-run the same test on your own institution's Turnitin before you submit.
What was the AI source for the 1,000 essays?
Inputs were generated across ChatGPT (GPT-4o, GPT-5), Claude (Sonnet 4.5 and Opus 4.7), and Google Gemini 2.5 — the three model families that dominate student usage in 2026. Essays ranged from 300 to 2,500 words across argumentative, narrative, research-paper, lab-report, and literature-analysis formats. We did not include code, datasets, or non-English text.
Did you also test the free Origin model?
Origin was the control. On the same sample, the Origin model — which is free with no per-request word cap — targets a 99% pass rate on Turnitin, while Cohera (a Jarvis sub-model on the Premium tier) returned 100% pass in our internal sample. Both numbers are internal; both should be re-verified by the reader on their own text.
Can I see the raw data?
The aggregate scores from the parsed 20-PDF sub-sample are published in `research/internal-reports/parsed/aggregate-scores.md` in our repository. Per-essay text is not published to protect the privacy of the users whose content seeded the sample. Job IDs and cache keys for every detector run are stored in our ai_reports table and can be re-pulled on request.
Will Cohera work on every essay, every time?
No tool can promise that against detectors that update their models continuously. Cohera scored 100% pass on this sample at the time of testing. We re-run the benchmark monthly and publish results when detector vendors ship a model update. Verify your own output before you submit — the Proof Report is built for exactly that.



